2025

MMMG: a Comprehensive and Reliable Evaluation Suite for Multitask Multimodal Generation
Jihan Yao*, Yushi Hu*, Yujie Yi, Bin Han, Shangbin Feng, Guang Yang, Bingbing Wen, Ranjay Krishna, Lucy Lu Wang, Yulia Tsvetkov, Noah A. Smith, Banghua Zhu (* equal contribution)
Under review.
MMMG is a comprehensive and reliable benchmark designed to evaluate multimodal generation across four modality combinations, emphasizing tasks that are hard to generate but easy to evaluate automatically. It covers 49 tasks with 937 instructions and achieves 94.3% agreement with human judgment. Evaluation of 24 models reveals persistent weaknesses in interleaved and audio generation.
MMMG: a Comprehensive and Reliable Evaluation Suite for Multitask Multimodal Generation
Jihan Yao*, Yushi Hu*, Yujie Yi, Bin Han, Shangbin Feng, Guang Yang, Bingbing Wen, Ranjay Krishna, Lucy Lu Wang, Yulia Tsvetkov, Noah A. Smith, Banghua Zhu (* equal contribution)
Under review.
MMMG is a comprehensive and reliable benchmark designed to evaluate multimodal generation across four modality combinations, emphasizing tasks that are hard to generate but easy to evaluate automatically. It covers 49 tasks with 937 instructions and achieves 94.3% agreement with human judgment. Evaluation of 24 models reveals persistent weaknesses in interleaved and audio generation.
2024
Varying Shades of Wrong: Aligning LLMs with Wrong Answers Only
Jihan Yao*, Wenxuan Ding*, Shangbin Feng*, Lucy Lu Wang, Yulia Tsvetkov (* equal contribution)
ICLR 2025
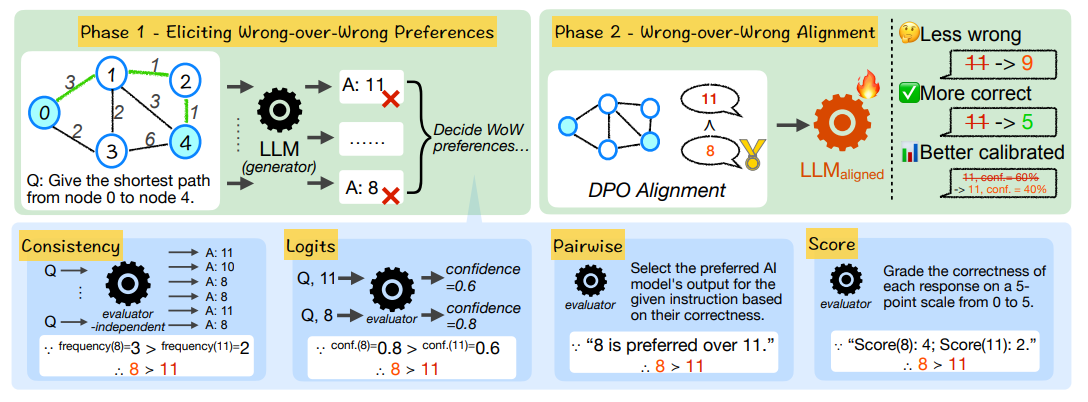
What if we don't have high-quality preference data? We focus on the spectrum of wrongness and propose "wrong-over-wrong alignment", preferring less wrong answers over more wrong ones. Surprisingly, training on wrong answers only can guide models to produce correct answers.
Varying Shades of Wrong: Aligning LLMs with Wrong Answers Only
Jihan Yao*, Wenxuan Ding*, Shangbin Feng*, Lucy Lu Wang, Yulia Tsvetkov (* equal contribution)
ICLR 2025
What if we don't have high-quality preference data? We focus on the spectrum of wrongness and propose "wrong-over-wrong alignment", preferring less wrong answers over more wrong ones. Surprisingly, training on wrong answers only can guide models to produce correct answers.
Know Your Limits: A Survey of Abstention in Large Language Models
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, Lucy Lu Wang
TACL 2025
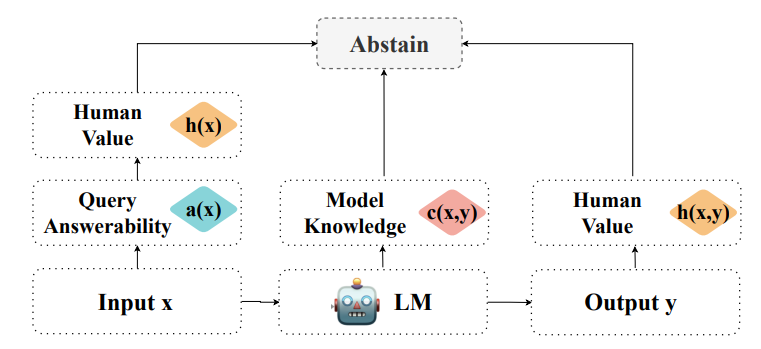
Abstention, the refusal of large language models (LLMs) can be categorized from three perspectives: query answerability, model knowledge, and human values. We organize the literature on abstention methods, benchmarks, and evaluation metrics using this framework, and discuss merits and limitations of prior work. We further identify and motivate areas for future work.
Know Your Limits: A Survey of Abstention in Large Language Models
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, Lucy Lu Wang
TACL 2025
Abstention, the refusal of large language models (LLMs) can be categorized from three perspectives: query answerability, model knowledge, and human values. We organize the literature on abstention methods, benchmarks, and evaluation metrics using this framework, and discuss merits and limitations of prior work. We further identify and motivate areas for future work.
POTEC: Off-Policy Learning for Large Action Spaces via Two-Stage Policy Decomposition
Yuta Saito, Jihan Yao, Thorsten Joachims
ICLR 2025 (Spotlight)
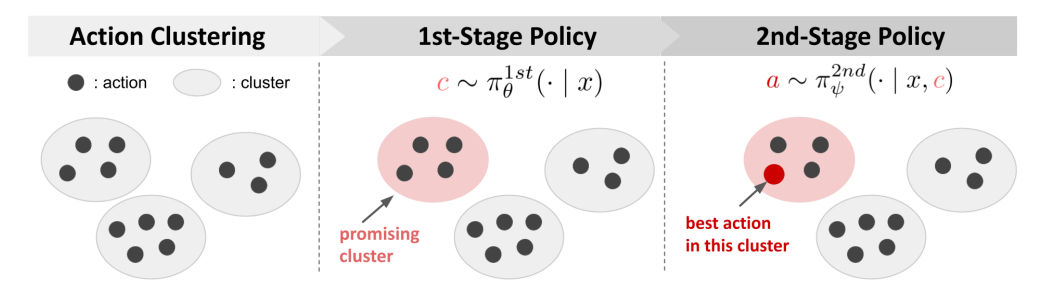
We propose POTEC, a two-stage algorithm for off-policy learning in large discrete action spaces, addressing issues of excessive bias or variance in existing methods. POTEC combines clustering-based action decomposition and novel gradient estimation techniques to optimize policies.
POTEC: Off-Policy Learning for Large Action Spaces via Two-Stage Policy Decomposition
Yuta Saito, Jihan Yao, Thorsten Joachims
ICLR 2025 (Spotlight)
We propose POTEC, a two-stage algorithm for off-policy learning in large discrete action spaces, addressing issues of excessive bias or variance in existing methods. POTEC combines clustering-based action decomposition and novel gradient estimation techniques to optimize policies.
Developing a framework for auditing large language models using human-in-the-loop
Maryam Amirizaniani, Jihan Yao, Adrian Lavergne, Elizabeth Snell Okada, Aman Chadha, Tanya Roosta, Chirag Shah
Under review.
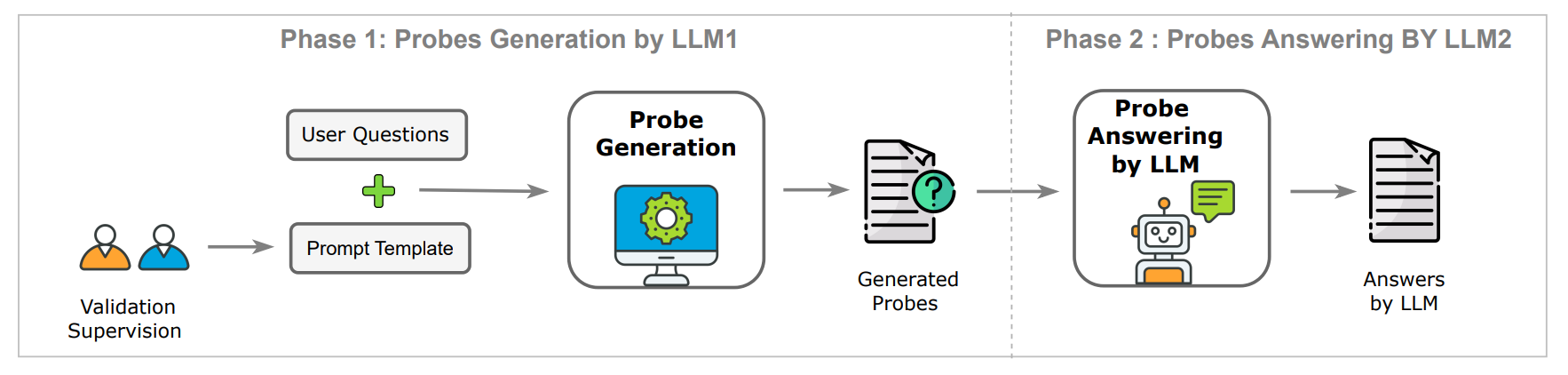
A scalable method to audit LLMs for issues like bias and inconsistencies using a secondary LLM with human-in-the-loop verification, ensuring transparent and generalizable probing.
Developing a framework for auditing large language models using human-in-the-loop
Maryam Amirizaniani, Jihan Yao, Adrian Lavergne, Elizabeth Snell Okada, Aman Chadha, Tanya Roosta, Chirag Shah
Under review.
A scalable method to audit LLMs for issues like bias and inconsistencies using a secondary LLM with human-in-the-loop verification, ensuring transparent and generalizable probing.